CLIENT’S NEED
Any company, regardless of its size or sector, must include a document control and monitoring system. Traditionally, an account book was used, which, with the advancement of technology, became a digital accounting system. However, today the paper format is still used for certain documents (invoices, tickets, delivery notes) that need to be digitalized to integrate the basic accounting data in the company's ERP (Enterprise Resource Planning system).
Normally this procedure goes through a person reviewing the invoice or ticket and individually typing the different relevant data of the document: the total cost, the different tax bases, CIFs, IBANs, dates, etc. Transcribing a complex invoice can take more than 2 minutes for an experienced person. This manual and tedious work involves a substantial personnel load; either by the accounting department of the company or outsourced through an external consultancy. In either case, it gives rise to inefficiencies, errors, and delays.
Infoqus, as a business consulting expert in information and management systems, needed a more efficient method for processing the documents it offers its clients. Biyectiva proposed a system based on Artificial Intelligence for the automatic extraction of fields and product lines in invoices, tickets and delivery notes.

CHALLENGES AND DIFFICULTIES
The heterogeneity with which invoices, tickets, or delivery notes are generated by companies makes it necessary to have an intelligent system that can robustly deal with the great diversity of formats of these documents. Template-based systems have shown that it is impractical to have to define different templates for each of the potential invoices that a company may receive. Therefore, one of the key difficulties of this project was to develop a sufficiently broad and flexible Artificial Intelligence that could detect fields in invoices, tickets, and delivery notes regardless of their format.
The design of a system with these characteristics required a huge set of data (or dataset) with which to “train” the Natural Language Processing systems. Another fundamental challenge in this project was to build a dataset of more than 10,000 invoices with precise annotations. To do this, it became essential to develop a proprietary document labeling tool that would speed up this process. The system, of course and inexcusably, had to offer very high detection accuracy; enough to ensure that the system really was reliable. An accuracy target greater than 90% was established.
Furthemore, as a fundamental requirement of the project, we had to build a system that was scalable. The initial objective was to be able to process more than 3 million invoices per year, with very large peaks at the end of the quarter (times of greatest load in consultancies).
SOLUTIONS
Given the technical complexity of this project, a start of the art analysis in Natural Language Processing and data fusion techniques with visual cues (indicators extracted with Computer Vision techniques that support semantic data extraction) was paramount.
The need for scalability and robustness ruled out the use of in-house servers right away. Instead, we opted for a complete cloud architecture. The fully distributed, docker-izable and manageable system architecture was designed using Kubernetes. Of course, given the complexity of the architecture, it was crucial to implement a real-time logging and monitoring system supported by the ELK stack with a custom real-time alert system.
To offer the service, a RESTful API was chosen that offered clear and well-documented interfaces. In this regard, in the Biyectiva team we were aware of the need for a great documentation effort, both internal (services, architecture) and external (use of the API, user management, etc.) in order to achieve the desired objectives.
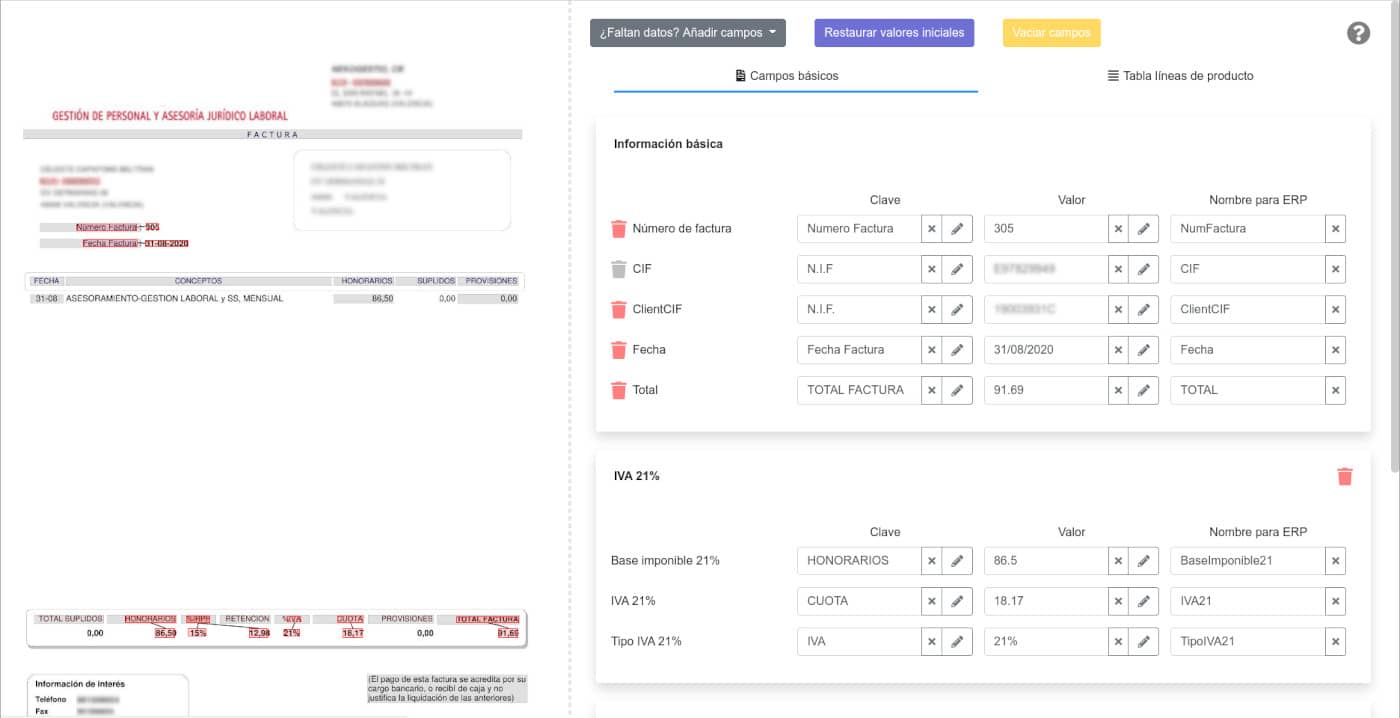
RESULTS
The system today is used by more than 30 different companies throughout the country, currently operating with an average load of 1 million total annual invoices. These figures guarantee that the benchmarks of robustness and scalability have been successfully achieved. The system developed by Biyectiva is capable of reading monetary values such as totals, the various Tax Bases, VATs, invoice numbers, IBANs, etc. It is even capable of extracting product lines from invoices and delivery notes to simplify cost accounting.
On the other hand, the accuracy in the detection of the different fields of invoices, tickets, and delivery notes is greater than 91%, demonstrating the reliability of the Computer Vision and NLP techniques.
For more information, we have published the necessary documentation here:
https://www.biyectiva.com/docs/